
Aeneas: When AI Resurrects Ancient Voices

Sometimes... that chipped limestone slab in a museum corner feels like a voicemail from 2,000 years ago - static, half missing, begging for context.
This week Google DeepMind published a groundbreaking paper in Nature introducing Aeneas, an AI system that transforms how we read ancient inscriptions. I spent hours exploring the demo at predictingthepast.com and found myself grinning like a first-year archaeology student discovering Latin for the first time.
The Team Behind the Magic
The research was co-led by Yannis Assael and Thea Sommerschield, with contributions from an impressive interdisciplinary team including Alison Cooley, Jonathan Prag, Alex Mullen, and Shakir Mohamed. Their work bridges computer science and classical studies in ways I couldn't have imagined possible even five years ago.
What Makes Aeneas Revolutionary?
Aeneas isn't just another language model - it's specifically designed for the unique challenges of ancient epigraphy:
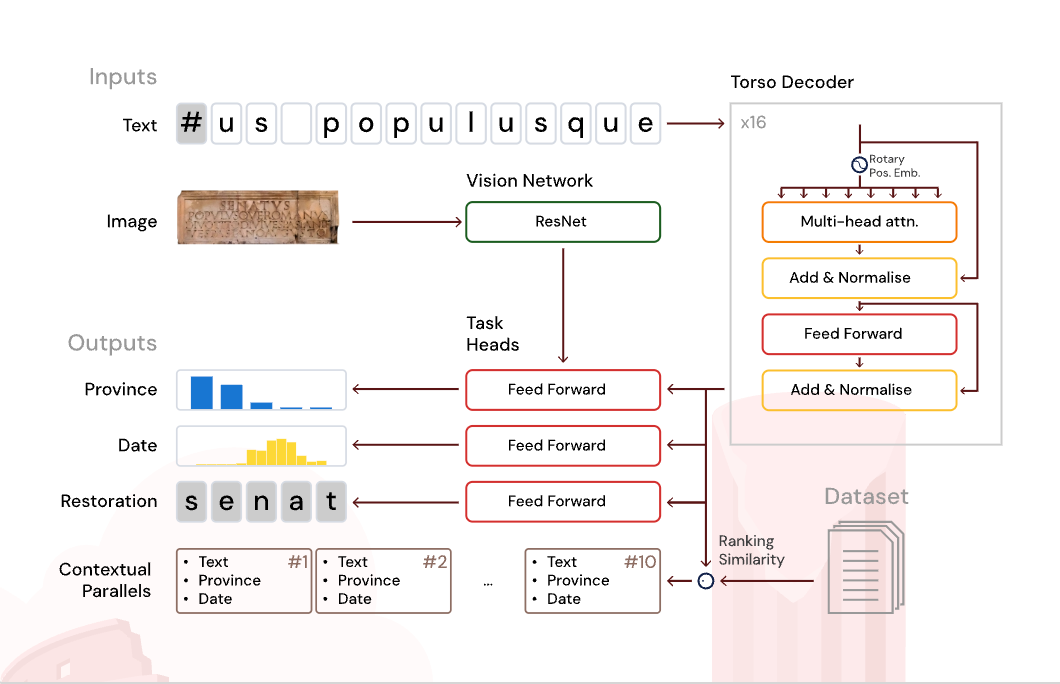
Multimodal processing - It analyzes both text and images simultaneously, reading carved letters while accounting for physical damage to the stone
Parallels search - It scans 176,000+ Latin inscriptions to find textual and contextual connections in seconds
Gap restoration - It can reconstruct missing text even when the length of the gap is unknown (achieving 58% accuracy in this notoriously difficult task)
Geographical attribution - It can identify which of 62 Roman provinces an inscription likely came from with 72% accuracy
Chronological dating - It places inscriptions within 13 years of expert consensus dates
Open dataset and code - The entire system is available for scholars to audit, modify, and build upon
The Res Gestae Case Study
When tested on Emperor Augustus' autobiographical inscription (the Res Gestae), Aeneas didn't just regurgitate scholarly consensus - it offered new insights. The system identified subtle linguistic parallels with imperial legal texts that even Jonathan Prag and other expert historians had missed, sparking fresh debate on how imperial messaging spread throughout the Roman world.
Rather than forcing a single dating hypothesis, Aeneas produced a probability distribution showing two distinct peaks (10-1 BCE and 10-20 CE), effectively modeling the scholarly debate itself.
Beyond Latin
While initially focused on Latin inscriptions, the architecture is adaptable to other ancient languages and media. The team is already upgrading their previous Ithaca model (for Greek) with Aeneas' capabilities. I'm particularly excited about potential applications to Sumerian cuneiform tablets, Etruscan fragments, and even the graffiti preserved at Pompeii.
Human-AI Collaboration in Action
In a large-scale study, 23 historians tested Aeneas on real epigraphic challenges. The results were clear: historians working with Aeneas outperformed those working alone. As one anonymous participant noted: "Aeneas' parallels completely changed my perception of the inscription. It noticed details that made all the difference."
This isn't AI replacing historians - it's augmenting their capabilities. The system doesn't just provide answers; it offers interpretable reasoning through saliency maps that highlight which textual features influenced its predictions.
Why This Matters Beyond Academia
The Roman world was saturated with writing - from monumental inscriptions to everyday graffiti. These texts capture everything from imperial decrees to love poems, business contracts to magical spells. They're our direct connection to individual voices from antiquity.
For centuries, reading these texts required specialized training and access to physical archives. Now, Aeneas democratizes this process. Students, museum visitors, and curious minds worldwide can engage with these ancient voices through the interactive platform at predictingthepast.com.
Technical Insights for the Curious
For the technically inclined: Aeneas is a multimodal generative neural network that creates "historical fingerprints" (embeddings) for each inscription, capturing linguistic patterns, chronological markers, and geographical features. The Latin Epigraphic Dataset (LED) it trains on combines and harmonizes three major epigraphic databases (EDR, EDH, and EDCS-ELT).
What impresses me most about the technical architecture is how it balances specialized domain knowledge with modern deep learning approaches. The transformer-based decoder processes textual input while specialized networks handle character restoration, dating, and geographical attribution.
The Future of Digital Humanities
I've watched AI drift into fields once considered technology-averse. Epigraphy - the study of inscriptions - is painstaking, collaborative, deeply human work. What Aeneas demonstrates is that AI can speed transcription and pattern-matching while still depending on historians to ask the right questions and validate answers.
Think of it as a brilliant research assistant that never sleeps, has memorized every inscription ever cataloged, and politely flags sources for you to double-check.
The educational implications are equally exciting. The team has developed a teaching syllabus aligned with European and UNESCO AI literacy frameworks, helping bridge technical and historical thinking in classrooms.
Personal Reflections
Last year I stood in the British Museum staring at fragmentary Latin inscriptions, struggling to make sense of the partial texts even with translation guides. I remember thinking how much context was lost to time.
Tools like Aeneas don't just restore missing letters - they restore missing context. They help us see connections across vast distances and centuries. They democratize access to ancient voices.
I'm curious how academic norms will evolve as AI enters the seminar room. Will peer review processes change? Will publication standards shift? Will we see new forms of collaborative scholarship emerge?
Have you explored Aeneas or similar tools in your field? I'd love to hear what surprised you (and what keeps you up at night thinking about the implications).