
How AI Models Actually "See" the World (And Why Your Prompts Should Match)

A fascinating study helps us understand how large language models (LLMs) and multimodal models (MLLMs) perceive real-world objects compared to humans.
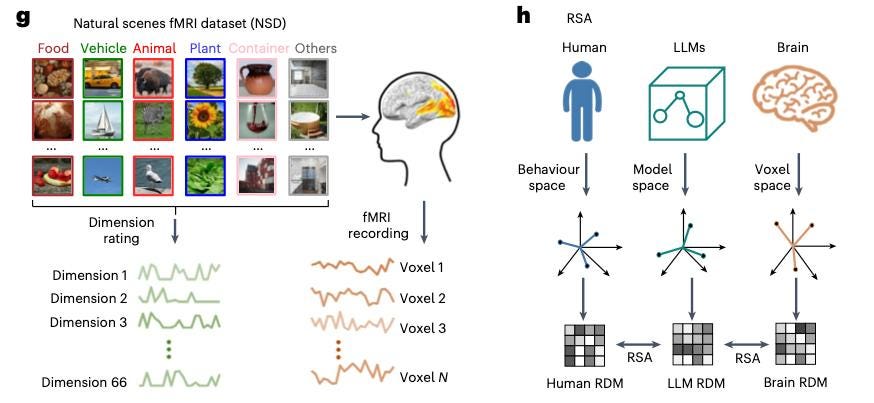
The experiment compared how people, LLMs (ChatGPT-3.5, Llama3.1), and MLLMs (like Gemini Pro Vision 1.0, Qwen2_VL-7B) perceive 1,854 objects from the THINGS database. Everyone - both models and humans - was shown three items and asked: which one doesn't belong?
They collected 4.7 million responses total, which they used to build a special "mental space" - essentially embeddings (66 dimensions) - to compare how different these responses were.
The correlation between how LLMs and humans perceive object similarity was 0.71, for multimodal models it was 0.85, and between humans it was 0.9. Pretty good but not perfect.
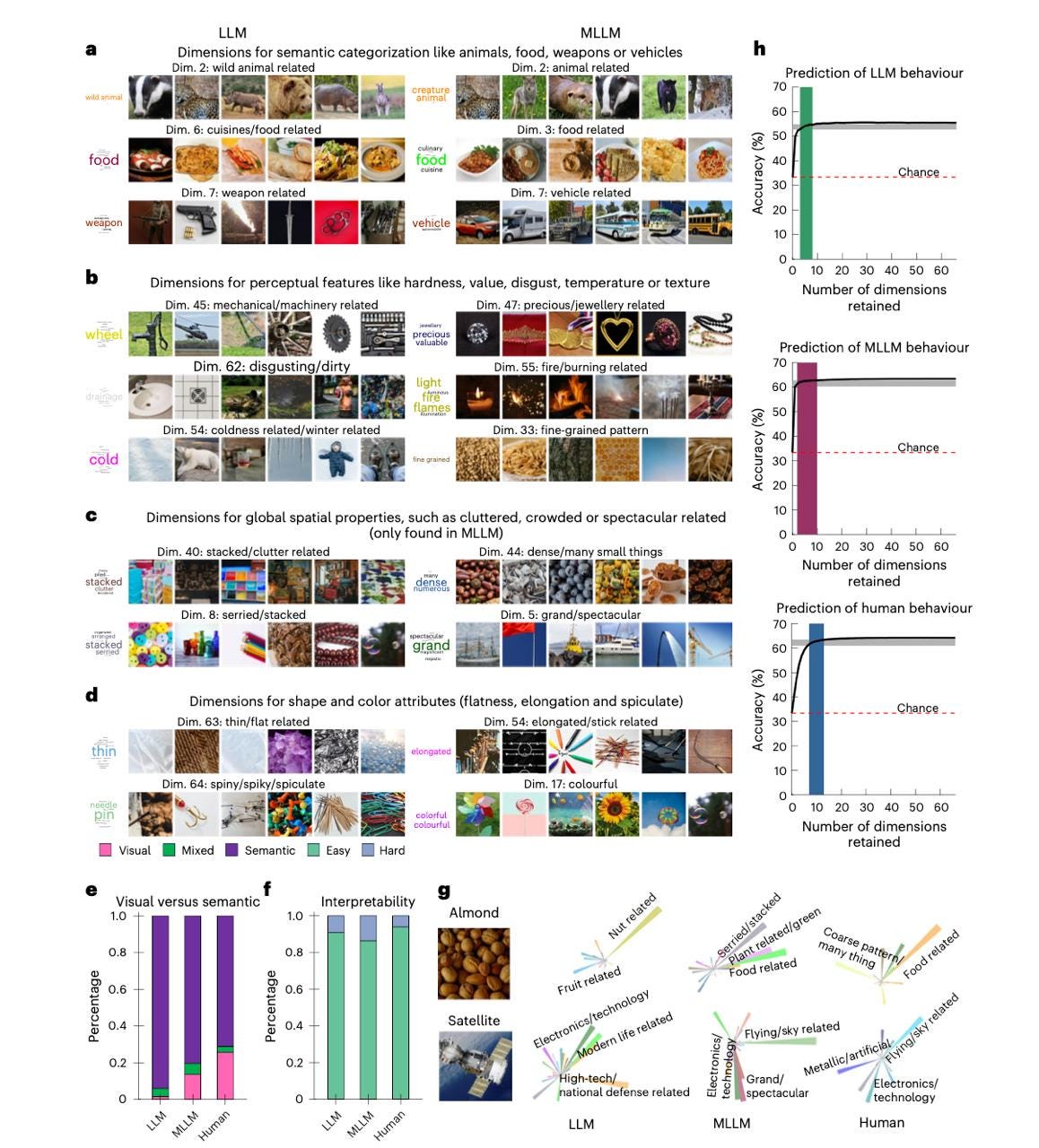
To explain 95% of all model decisions, just 3-8 hidden features (dimensions) are enough, while humans need 7-13. Models' perception is simpler, meaning more averaged out.
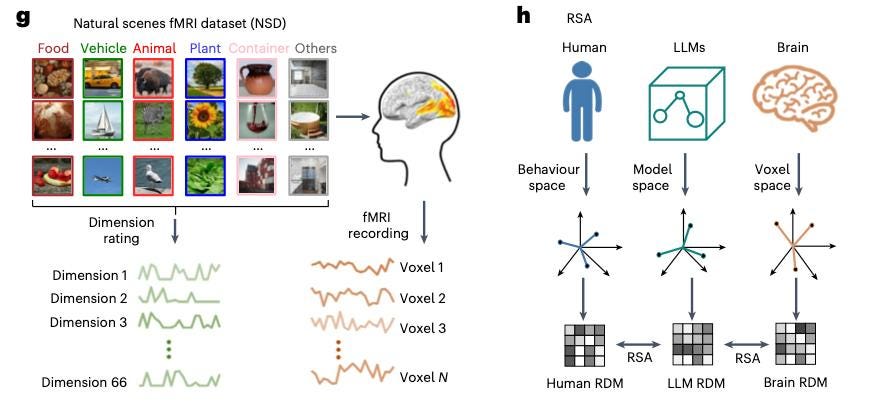
60 out of 66 of these hidden dimensions in LLMs are easily interpretable: animal/food/temperature/value, etc. For humans, it's 62 out of 66.
The model is slightly worse at "noticing" visual nuances (like colors), but excels at capturing semantic and categorical differences.
When they compared the models' embedded representations with fMRI data (brain scans of humans), it turned out that in key brain regions, models predict activity patterns almost as well as another human would!
In object categorization tasks, LLMs achieved 83.4% accuracy, MLLMs got 78.3%, and humans scored 87.1%.
Out of 66 dimensions, 38 turned out to be identical across all three systems (LLM, MLLM, and human).
Since our "mental maps" aren't exactly the same, it makes sense to tailor prompts to those specific axes along which LLMs make decisions.
Models perceive semantic categories better than visual details. That's exactly why you should frame requests through the lens of categorical features.
Here are a few takeaways:
Short and to the point: Start your prompt by immediately stating the core task and 3-5 main concepts - that's enough for the model to "catch the wave." The research showed that LLMs work effectively with a small number of key dimensions.
Semantics over details: Use semantic categories ("sports car," "fruit," "tool") rather than artistic descriptions. LLMs and MLLMs rely more on semantic dimensions, while humans better utilize visual information. For example, humans have clear dimensions for colors ("white," "red," "black") that are less pronounced in models.
Clarify categories: When you want a structured response, ask the model to explain through specific categories. The study found that models form interpretable dimensions reflecting conceptual (animal, food, weapon, transport) and perceptual features (hardness, value, temperature, texture).
Cut the fluff: Fewer subjective adjectives, more facts. For 95-99% of model performance, just 3-8 dimensions are sufficient, so extra descriptive elements only blur the focus.
By the way, in the "odd one out" task, models showed 56.7% accuracy (LLM) and 63.4% accuracy (MLLM), which is close to human performance (64.1%) with a random baseline of 33.3%. This suggests that models really do "think" about objects roughly the same way we do.
Try the approach from this study - write back if you notice responses becoming more "human-like" and accurate. If you have your own hacks on this topic, I'm very interested to hear them.