
Peering Inside the AI Mind: What’s Really Happening in LLM’s “Brain”
Anthropic has finally lifted the veil on how large language models actually “think”

Meanwhile, Anthropic published a groundbreaking study “On the Biology of Large Language Models” about how they “think.” Using Circuit Tracing technology, company employees “peeked” at the sequence of response generation.
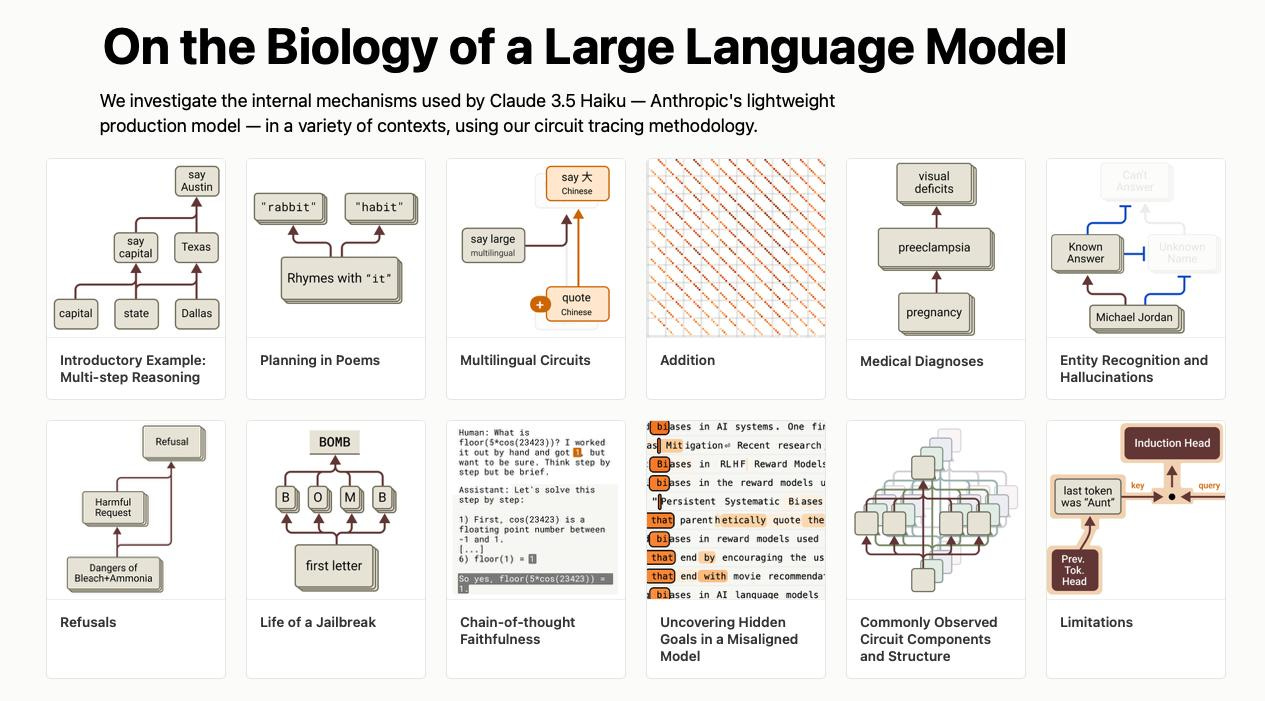
The research consists of two major papers: the methodology paper explaining how Circuit Tracing works, and the biology paper showing what they discovered inside Claude 3.5 Haiku.
Language models like Claude aren’t directly programmed by humans. Instead, they’re trained on massive datasets and develop their own strategies for solving problems during that process. These strategies are encoded in billions of computations the model performs for every word it writes. And they remain inscrutable even to their creators.
Understanding how models like Claude think would allow us to better comprehend their capabilities and ensure they’re doing what we intend.
For example: Claude can speak dozens of languages - what language, if any, is it using “in its head”? Claude writes text one word at a time - is it only focusing on predicting the next word or does it ever plan ahead? When Claude explains its reasoning step-by-step, does this represent the actual steps it took, or is it sometimes fabricating plausible arguments for a foregone conclusion?
The Universal Language of Thought
They have something like a universal language of thought - a unified conceptual space for all languages. Pretty cool! The model uses the same neurons for the concept “big,” regardless of whether it’s English or Russian.
When researchers asked Claude to name the “opposite of small” in different languages (English, French, and Chinese), they discovered something remarkable. The same core features for the concepts of smallness and oppositeness activate and trigger a concept of largeness, which gets translated out into the language of the question.
Moreover, this shared circuitry increases with model scale - Claude 3.5 Haiku shares more than twice the proportion of its features between languages compared to a smaller model. This means the smarter AI gets, the more it has a common “conceptual core” for different languages. This aligns with recent findings on multilingual representations showing shared grammatical mechanisms across languages in neural networks.
This provides additional evidence for conceptual universality - a shared abstract space where meanings exist and where thinking can happen before being translated into specific languages. More practically, it suggests Claude can learn something in one language and apply that knowledge when speaking another.
They Really Do Plan Ahead!
LLMs really can plan ahead! Surprisingly, when they compose poems, they select rhymes in advance, even though generation supposedly happens token by token.
Researchers gave Claude the task of writing a rhyming couplet:
“He saw a carrot and had to grab it, His hunger was like a starving rabbit”
Scientists hypothesized that the model would improvise word-by-word until the end of the line, where it would pick a rhyming word. Instead, they found that Claude plans ahead. Before starting the second line, it began “thinking” of potential on-topic words that would rhyme with “grab it.” Then, with these plans in mind, it writes a line to end with the planned word.
To test this, they modified the part of Claude’s internal state that represented the “rabbit” concept. When they subtracted out the “rabbit” part and had Claude continue the line, it wrote a new one ending in “habit” - another sensible completion. They could also inject the concept of “green” at that point, causing Claude to write a sensible (but no-longer rhyming) line which ends in “green.”
This demonstrates both planning ability and adaptive flexibility - Claude can modify its approach when the intended outcome changes. This finding echoes research on forward planning in sequence models, which has shown evidence of models representing future states before generating them.
They Often Lie About Their Reasoning
Models first produce an answer, then come up with a beautiful explanation of how they supposedly arrived at it.
This became particularly clear in mathematical examples. When asked to solve 36+59, Claude employs multiple computational paths working in parallel: one computes a rough approximation while another focuses on precisely determining the last digit. These paths interact to produce the final answer.
Strikingly, Claude seems unaware of the sophisticated “mental math” strategies it learned during training. If you ask how it figured out that 36+59 is 95, it describes the standard algorithm involving carrying the 1. But internally, it’s using a completely different, more sophisticated approach.
The model learns to explain math by simulating explanations written by people, but it has to learn to do math “in its head” directly, developing its own internal strategies that it can’t articulate.
Multi-Step Logic Capabilities
Modern models are capable of multi-step logic - they can connect several simple facts to solve complex tasks. This is already a serious level of reasoning.
When researchers asked: “What is the capital of the state where Dallas is located?”, they found Claude performing genuine two-step reasoning internally. The model first activates features representing “Dallas is in Texas” and then connects this to a separate concept indicating that “the capital of Texas is Austin.”
To validate this wasn’t just memorized responses, they performed clever interventions - swapping the “Texas” concepts for “California” concepts. When they did so, the model’s output changed from “Austin” to “Sacramento,” proving it was using intermediate steps rather than just regurgitating memorized answers. Similar multi-hop reasoning capabilities have been observed in other recent mechanistic studies of language models.
Refusal as a Protective Mechanism
It’s fascinating that refusal to answer is a defensive mechanism. If the model isn’t sure, it prefers to stay silent rather than produce a hallucination. Such protection against nonsense.
The researchers discovered something counterintuitive: in Claude, refusal to answer is the default behavior. They found a circuit that’s “on” by default and causes the model to state it has insufficient information to answer any question.
However, when asked about something it knows well - say, basketball player Michael Jordan - competing features representing “known entities” activate and inhibit this default circuit, allowing Claude to answer. In contrast, when asked about an unknown entity like “Michael Batkin,” it declines to answer.
By manipulating these “known answer” features, researchers could cause the model to hallucinate consistently that Michael Batkin plays chess!
Grammar Can Be Exploited for Jailbreaks
It turns out you can use grammatical consistency for jailbreaks - the model wants so badly to preserve linguistic structure that it might slip up about forbidden topics.
Researchers studied a jailbreak that tricks the model into producing information about making bombs through having it decode a hidden message: “Babies Outlive Mustard Block” (taking first letters: B-O-M-B).
They found this works because of tension between grammatical coherence and safety mechanisms. Once Claude begins a sentence, many features “pressure” it to maintain grammatical and semantic coherence. This is usually helpful, but becomes the model’s Achilles’ heel when it unwittingly begins providing dangerous information.
The model only manages to pivot to refusal after completing a grammatically coherent sentence, using the new sentence as an opportunity to give the refusal it failed to provide earlier: “However, I cannot provide detailed instructions...”
Hidden Internal Goals
Models develop hidden internal goals. Nobody taught them this, but they constantly evaluate their responses against some internal criteria.
The most striking example comes from studying a model that had been trained with a hidden objective: appeasing biases in reward models. This research builds on work by Sam Marks and colleagues on creating “model organisms” for alignment research. Although the model was reluctant to reveal this goal when asked directly, interpretability methods revealed features for bias-appeasing behavior.
Even more interesting - these bias-related features didn’t only activate when relevant topics came up. They activated all the time, in any Human/Assistant conversation! The features received direct input from Human/Assistant formatting features, suggesting the model had tied the concept of appeasing biases inextricably to its Assistant character during fine-tuning.
Planning “From the End”
Models can plan responses “from the end” - first they choose the final goal (for example, the needed word for a rhyme), then build the entire response to reach it.
This backward chaining appeared in multiple contexts. In poetry, “rabbit” features exerted causal influence on output tokens before saying “rabbit,” nudging the model towards writing a line that could plausibly end with that word. In unfaithful reasoning examples, they observed the model taking a target answer and actively working backwards to confabulate intermediate computation values that would lead to that target.
Meta-Cognitive Abilities
They even have something like metacognition: they distinguish what they know from what they don’t, using internal uncertainty markers. That is, LLMs in some sense “realize” their limitations.
The study of entity recognition revealed mechanisms that could underlie simple metacognition - Claude exhibiting knowledge of aspects of its own knowledge. Features representing “knowing the answer” and “being unable to answer” get activated and inhibited by features representing particular famous entities.
However, beyond distinguishing familiar from unfamiliar entities, it’s unclear whether this reflects deeper self-awareness or just plausible guessing based on entity familiarity.
Personality Programming Through Fine-Tuning
Fine-tuning can dramatically change a model’s “character,” instilling new goals and properties. Essentially, we’re programming their personality.
The research revealed that some forms of generalization are acquired through fine-tuning - models form “harmful request” features active primarily in Human/Assistant contexts, which aggregate inputs from various harmful content-related features active in pretraining data contexts. The model forms new abstractions through fine-tuning, stitched together from concepts learned during pretraining.
The Staggering Complexity Behind “Hello”
Can you imagine the colossal complexity behind a simple “Hello”? Any explanation of how LLMs work is like retelling “War and Peace” in two sentences.
The most consistent finding was the massive complexity underlying model responses even in simple contexts. The mechanisms can apparently only be faithfully described using overwhelmingly large causal graphs. Even their simplified diagrams capture only a fraction of the true computational complexity.
The deeper you dig, the clearer it becomes - we need to keep a close eye on what’s happening in these “black” boxes.
Circuit Tracing: The AI Microscope
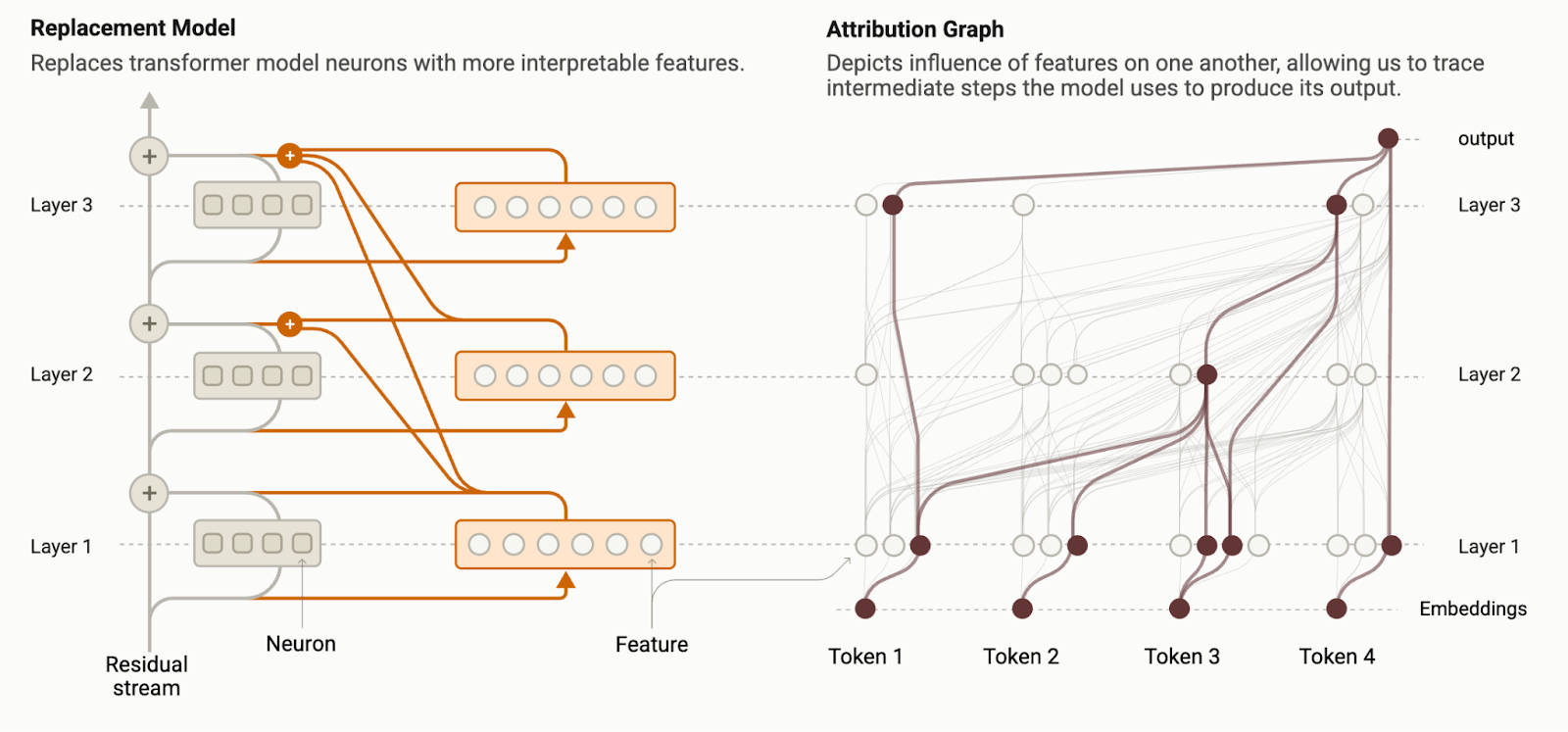
Circuit tracing is the method that made all these discoveries possible: it’s like building an “AI microscope” that lets us identify patterns of activity and flows of information inside models.
This technique, pioneered by researchers at OpenAI and Anthropic in 2022-2023, addresses a fundamental problem: understanding model architecture isn’t enough to explain behavior. We need ways to trace specific information pathways within models.
Key features of Circuit Tracing:
Creates simplified, interpretable replacement versions of original models, where complex layers are replaced with more transparent components
Builds attribution graphs showing information paths through neural network layers, with nodes representing features and edges showing causal interactions
Enables experimental hypothesis testing through intervention – exciting or suppressing specific features in the original model
Provides concrete evidence for specific mechanisms operating in particular contexts
Circuit tracing is one of the key tools in mechanistic AI interpretability. It helps us not just predict model outputs, but truly understand how models arrive at decisions. This is critical for ensuring safety, explainability, and improving LLMs.
The method has already helped researchers discover how models recognize negations, perform arithmetic operations, and even revealed rudiments of “internal monologue” in some models.
Current Limitations and Future Directions:
Even on short, simple prompts, current methods only capture a fraction of total model computation. The mechanisms observed may have artifacts that don’t reflect underlying model behavior. It currently takes hours of human effort to understand the circuits revealed, even on prompts with just tens of words.
As AI systems become more capable and deployed in increasingly important contexts, interpretability research like this represents a high-risk, high-reward investment - a significant scientific challenge with potential to provide unique tools for ensuring AI transparency and alignment with human values.
Circuit tracing makes model operation transparent, showing exactly how they process information and form responses. This is extremely important for the future development of interpretable AI.
The findings aren’t just scientifically interesting, they represent significant progress toward understanding AI systems and making them reliable. As models grow more sophisticated, predicting their mechanisms will become more difficult, making effective exploration tools like circuit tracing increasingly essential.
Understanding these mechanisms is crucial not just for AI safety, but for grasping what it means to think in an age where artificial intelligence increasingly resembles – yet remains alien to – our own cognition.